
Updated on
Data-centric AI, the road less traveled
The last decade has seen rapid advances in AI with a plethora of deep learning frameworks, architectures, and models, well supported by advances in computing resources. Currently, we have a reasonably good number of models for NLP, vision, speech, spatial analysis etc. On the language modeling side, we see companies and research institutes competing with each other to bring out the largest model ever. From a few million parameter models, the ecosystem has quickly transformed into billions of parameters and soon we may see trillion parameter models.
In October 2021, Microsoft and Nvidia announced that they had trained the largest and most capable AI-powered language model to date: Megatron-Turing Natural Language Generation (MT-NLG) consisting of 530 billion parameters and that achieves unmatched accuracy in a broad set of natural language tasks such as reading comprehension, commonsense reasoning, and natural language inferences. On the computer vision front, researchers at Google Brain announced a deep-learning computer vision (CV) model containing two billion parameters. The model was trained on three billion images and achieved 90.45% top-1 accuracy on ImageNet, setting a new state-of-the-art record.
The common denominator across all these models is availability of large volumes of publicly available data, state-of-art baseline models, and less expensive computing resources. The focus has been on getting out the next biggest model which would outperform the other. These language and vision models are useful for use cases involving Q&A, conversational bots, search, summarization, language generation, translation, image classification, object detection etc. Though the objective of such models is to create generalized models that can handle multiple scenarios, one of the challenges of these large models is their sheer size and low compatibility with domain adaptation. Though these models provide broader capabilities across a spectrum of use cases, how well they handle acceptable levels of performance in narrow use case settings is debatable.
As AI practitioners, in the model-centric approach, the general practice is to directly consume open-source models, perform transfer learning or knowledge distillation, and adapt it for the intended purpose. In the model-centric approach, the data is held constant while the model architecture is iterated to improve performance. The focus is on model fine-tuning, optimization, quantization etc. Currently with the advent of AutoML, a lot of these processes are getting automated and will soon get commoditized. If everyone gets the same model, and applies AutoML and hyperparameter tuning, then where does the differentiation come in? In the pursuit to get the next best model, a generation of practitioners have given undue importance to models compared to what they are doing with the underlying data. In traditional ML, the thumb rule is that 80% effort goes into data collection, cleaning, preparation, and feature engineering and only 20% into modeling. In the case of AI models, somehow there was a deviation from this thumb rule and a lot of importance went into models. The focus was on processing Big Data and the laborious task of understanding the data, assessing its distribution, checking its quality, labeling etc. got outsourced. This led to an ambiguous understanding of the data. The task of improving model performance is being achieved through model tuning and not data tuning.
If data has noise, incorrect and inconsistent labels, and imbalanced distribution, would fine-tuning the model to improve performance give results? The need of the hour is to get back to basics.
A data-centric approach to AI is fundamental to improving the performance of AI models beyond model optimization. As per Andrew Ng, leading AI expert, “Data-centric AI is the discipline of systematically engineering the data used to build an AI system.” In a data-centric approach, the focus is on measuring data quality, fixing labeling inconsistencies and augmenting data while the model is held intact.
How do we approach Data-Centric AI?
Following are key design principles to pursue data-centric AI.
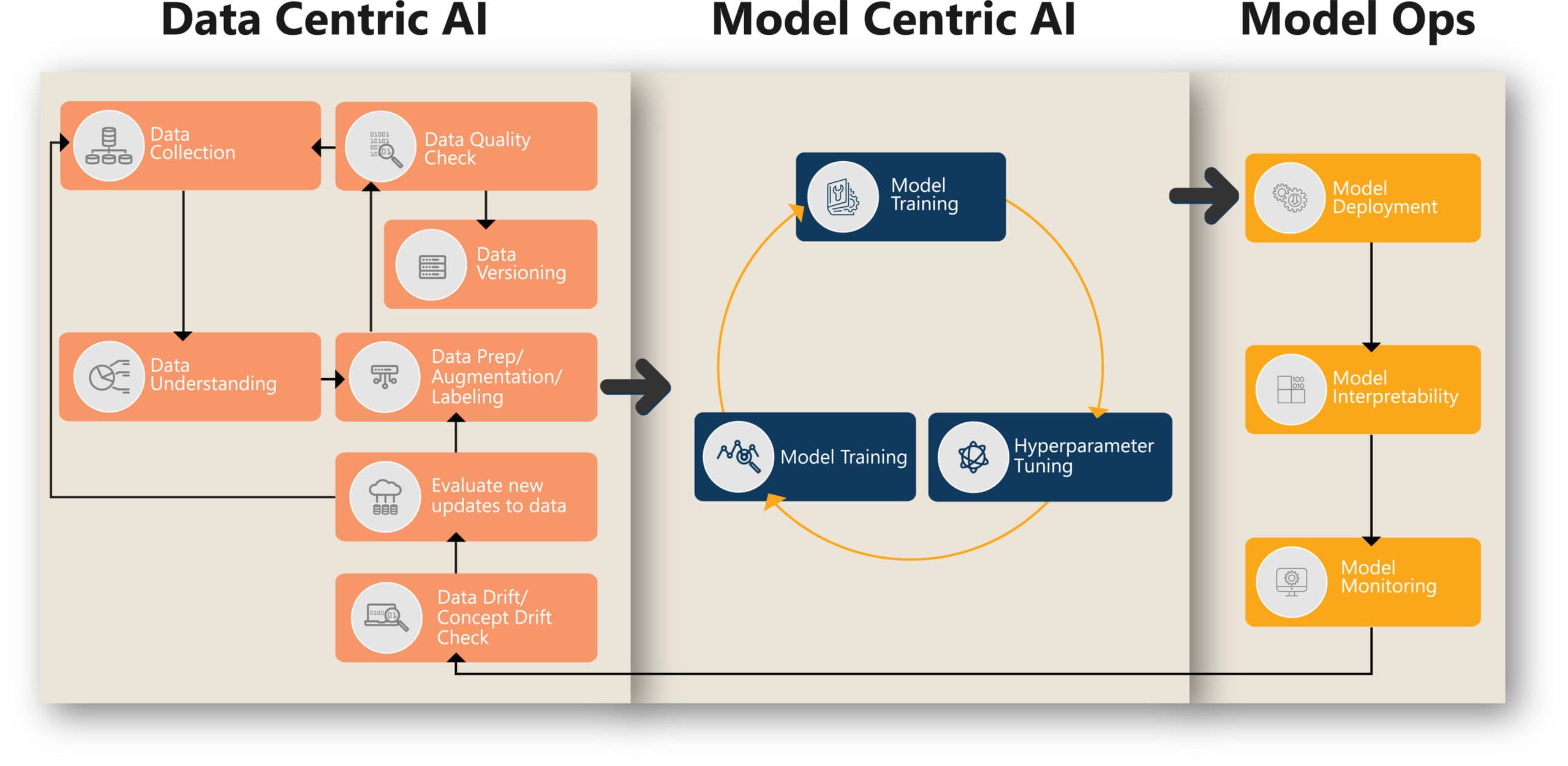
Data Profiling:
It is important to get a comprehensive view of the data covering metadata of the dataset, its distribution, features, biases, measure of missing data, noise, time period of the data, size of the data etc. Involving domain experts would enhance data scientists’ ability to get a better understanding of the data. The focus is on quality of data than quantity of data.
Data Labeling quality:
The main goal is to ensure consistency in data labeling. There is a need to publish annotation guidelines to ensure that labeling is done in a consistent way by annotators and there is no deviation. The labeled data must be checked by AI scientists as reviewers and any defects identified must be fixed. It’s key to ensure consistently high-quality data in all phases of the ML project lifecycle. The quality of the model is highly dependent on the quality of the labeled data.
Data Augmentation:
Data augmentation helps in multiple ways. For example, when there is imbalance in the data or if the overall sample size is small in a computer vision use case, data augmentation helps to upsample classes with less data by employing various techniques such as varying the orientation, adding Gaussian noise, blurring, cropping, intensity/contrast variation etc. For NLP tasks, there are techniques to paraphrase, mask, random insertion, random swap, synonym replacement etc.
Data Versioning:
An audit trail of the data used for modeling is important to ensure reproducibility and reliability of the models. It subsequently helps to compare different model versions when they are trained on different datasets and take informed decisions for further improvement.
Model Interpretability:
This is a very important activity to understand what the model has learned from the training data, how well it performs inferencing, which segment of the data is more influential, and which are not in decision making.
Data Drift:
It’s impractical to have all the variations in data during model training. Post deployment, models would encounter data drift and concept drifts. It’s important to monitor the change in data behavior on a continuous basis and retrain when preset thresholds are breached.
In the vast majority of industries, the use cases we encounter would involve small data. For example, detecting product surface quality defects in manufacturing lines, identifying diseases in medical scans, detecting packaging defects in Retail/CPG, detecting fraud in financial transactions etc. The objective is to detect anomalous behavior which is a rare event. The data-hungry model-centric approach may not serve the purpose. At Course5 Intelligence, we have been pioneering data-centric AI for our flagship product, Course5 Discovery, which is an augmented analytics platform and provides insights to users in an interactive search mode. Business users have a limited number of high-value questions that they need answers for to make impactful decisions. The input is small data. We have applied data augmentation to multiply training data, ensured quality of labeled data, versioned the data and we monitor a new set of questions that the system encounters to retrain the model at required intervals. This approach has helped us improve model performance consistently.
A hybrid approach with equal importance given to model-centric and data-centric AI would provide balanced results since it leverages the best of both worlds. However, the last decade has given substantial focus to model-centric AI. It’s the right time to bring the focus back to data-centric AI in this decade—cruise through the road less traveled—and cover the gap with advancements in model-centric AI.

Jayachandran Ramachandran
Jayachandran has over 25 years of industry experience and is an AI thought leader, consultant, design thinker, inventor, and speaker at industry forums with extensive...Read More


Don’t miss our next article!
Sign up to get the latest perspectives on analytics, insights, and AI.


